
Gateway Options: Text-to-Speech
When a phone call is answered, the system needs to play the message a) immediately for live human pickup, and b) until a beep sound is detected for answering machine or voice mail system. Based on the answering party, the system then decides whether to play or wait. Unfortunately, there is no tone or signal over the phone line that indicates the pickup situation. Hence the system has to analyze the audio stream over the phone line in order to make a decision.
What can complicate the detection process
Strong background noise can be hard to filter out, especially it is from a human voice. A loud TV in the background, a second person talking to other person, etc, can mislead the system to make an answering machine prediction for human pickup.
On the other hand, a very weak answering machine volume can be diagnosed as background noise. So the system might think it is a live human pickup and play the message too early.
Another factor is that people answer the phone differently. There are really no fixed patterns or even regular patterns to follow. People from different countries, from different ethnic groups also answer the phone differently.
Answering machine messages and voicemail prompts are very different too.
Phone company messages are also complicated. Some announcements start with a disconnected beep sound, others with a different beep, and the rest do not even have one.
The system has to make a decision in real
time
The system has to analyze the audio stream in real time so it can respond as soon as possible. This in certain degree limits what kind of algorithm the system can deploy. It is much harder to do it in real time with partial audio streams.
The system does make mistakes
As you can see, the prediction algorithm is based on statistics data. There is no guarantee the prediction is correct. We can always improve the accuracy and make the system more intelligent, but to reach 100% accuracy is impossible using today�s technology. The best system for prediction is the human perception system. But even humans make mistakes from time to time.
The choice is based on your application
In order to make the system more responsive to human
pickup, something has to give. And this something is the accuracy for answering
machine detection. If you care more about live human pickup and you can
tolerate more mistakes for answering machine, then you can make the algorithm
more responsive to humans.
Make it most responsive for live human pickup
On an extreme case, you can instruct the system not to do any answering machine vs. human analysis. Whenever the system hears a voice, it can start playing the message right away. Of cause, the system still needs some short time to recognize the human voice, filtering out the background noises, etc. The drawback is of this approach is that all answering machines will be treated as humans. The message will be played immediately after an answering machine answers the call. There will be no message, or only partial message, left on answering machines.
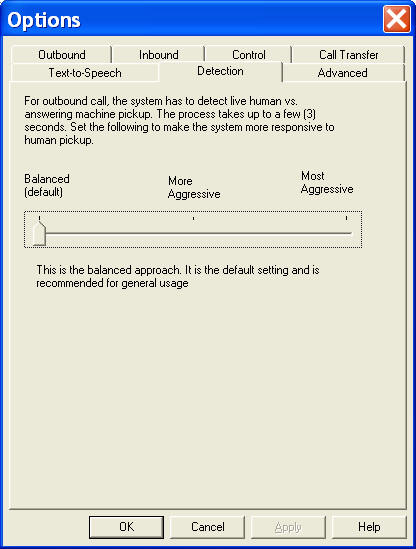
To set this option, please select Setup > Options� from the gateway main menu, then choose the Detection tab. Move the sliding control bar to the position marked Most aggressive.
The biggest problem of this approach is that no answering machine will be recognized. For general usage, this setting is not recommended.
Make it more aggressive more human pickup
The default setting is the balanced approach for humans vs. answering machines.
This is the default setting and it is recommended for general usage. The system
will try to make a prediction as soon as possible.
You can make the system to be more aggressive on human pickup without totally losing the ability of answering machine detection. You can set it prediction to be more aggressive on humans. In this setting, the system will try to make a prediction as soon as the audio is likely to be humans. But there will be more mistakes for answering machines.